今年1年間で行った転職活動について
はじめに
私はデータサイエンス未経験の会社員です。恐れ多いのですが、このアドベントカレンダーにも参加させていただきました。 ですので、みなさんのようなバリバリ実務に役立つような記事というのは書けないのですが、今回は私の転職活動について、そしてデータラーニングギルドという組織について、息抜きするような感じで書いていこうと思います。また、私はプログラミング実務未経験の超平凡な人間です。そんな私がデータラーニングというプログラミングスクールを経て、今年1年かけてWeb業界に参入しようと転職活動を行いました。
結論、内定をとることはできたが、転職することはせず、今の仕事をすることに^^
それでも転職活動したことやPythonを学んだことに後悔はありません。むしろ、今の自分の仕事に役立てることができている(と思いたい)ので、プラス効果です! 今年1年間を前半(1月〜6月)と後半(7月〜11月)に分けてつらつらと書きます。
前半(2023年1月〜6月)
1月にデータラーニングギルド内でオフ会イベントがありました、ギルド自体には2021年から所属していましたが、コロナ禍だったため、今回が初のオフ会参加です。さらにLTの発表も行いました。
いつもとは違う立ち位置での発表だったので緊張しましたが、そのあとの懇親会ではすごいといってもらえたのが冗談だったとしても嬉しかったです。
その後もイベントには参加するようにしました。4月での浅草橋オフ会、7月頃の東京タワーでのジンギスカンを食べながらのオフ会もとても楽しく過ごすことができました。 ・・・あれ転職活動については・・・(汗)
後半(2023年7月〜今)
というわけで、ここからが転職活動の開始、自分の作ったポートフォリオをgooglecolabにまとめたり、職務経歴書にソフトスキルをかきまくったりと、転職の準備!準備です!そして企業への応募!う〜ん書類がとおらない!!! それでも、送り続けると2社が最終選考まで進み、1社内定(web開発系エンジニア)とることができました。 結局内定を(家庭の事情のため)お断りすることにしたのですが、転職するぞ!と意気込んで実際に活動し、活動して行く中で本来の自分は?ってのも考える機会になりました。
それも単純で、ただただ楽しく毎日すごしたいんだなということでした。 転職しなかった理由はまだまだあるのですが、内容がまとまらないので、この辺にしておきます。。。
今後への意気込み
前半の経験から、データラーニングギルドのオフ会はいいぞ!実務未経験の自分でも楽しめてるのだから、きっと、前線で働いている人たちが集まれば会話が弾むだろうなって思っています!(混ざれない自分がくやしいいいい)
でもでも、今後も自分でPythonをいじりながら業務の効率化はこれからもこころがけていこうかなって思っています。 今回は転職しなかったけど、今後また気が変わってするかもしれない。 何はともあれ、今年はデータラーニングスクールありがとう!来年もまたデータラーニングギルドよろしくお願いします!
目指せ自動採点!(問題番号を消す編)
ブログの紹介
このブログは現役教員が独学でプログラミング(Python)を学習して採点アプリを作ろうと思い、試行錯誤しながら作成にあたっております。そして、学んだことをアウトプットすることで、意味を理解しようという目的で書き残しています。 そして完成にあたり、欠かせないのが「採点斬り」)。こちらをフル活用しつつ、作成にあたっております。ぜひ一度、手を動かしながら使用してみて欲しいです。
まとめ記事はこちらから
自動採点のまとめ記事はこちらにあります。まとめ部分の一部の紹介になります。
問題番号を消す
処理の流れは以下の通り。
- 問題番号の部分を白紙(white.jpg)の解答から検出
- しっかり検出できているか確認
- 塗りつぶし処理を開始
また、あらかじめ採点で切り取った画像(outputフォルダ)を別場所にコピー(deepフォルダ)しておき 、処理をしていきます。
以下、コードになります。
# 画像周りを白で塗るための関数
def line_square(img, bold=25):
img_line2 = cv2.line(img, (0,0), (0,img.shape[0]), (255,255,255), bold)# 左縦
img_line2 = cv2.line(img_line2, (0,0), (img.shape[1],0), (255,255,255), bold)# 上横
img_line2 = cv2.line(img_line2, (img.shape[1],0), (img.shape[1],img.shape[0]), (255,255,255), bold) # 右縦
img_line2 = cv2.line(img_line2, (0,img.shape[0]), (img.shape[1],img.shape[0]), (255,255,255), bold) # 下横
return img_line2
↓これが検出するための関数です。面積の値(floor)は適宜調整します。解答番号を四角で囲むための4つの頂点を出力します。
# 解答番号を検出するための関数
def Kensyutu(file, floor=100):
rects = []
x1=[]
x2=[]
y1=[]
y2=[]
# 画像の読み込み
img = cv2.imread(file)
# 読み込んだ画像まわりを白で塗る。塗りすぎに気を付ける。
img = line_square(img, bold=10)
# グレー画像にする
img_g = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.fastNlMeansDenoising(img_g, h=5)
# 膨張処理
ret3,th3 = cv2.threshold(gray,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
img_adth_er = cv2.erode(th3, None, iterations = 7)
img_adth_er = cv2.dilate(img_adth_er, None, iterations = 5)
# 白黒反転処理
img_adth_er_re = cv2.bitwise_not(img_adth_er)
# 画像の中の面積になるものを検出
contours, _ = cv2.findContours(img_adth_er_re, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for i,contour in enumerate(contours):
# 一定の値(今回は100)以上のもののみ、検出する。
if cv2.contourArea(contour) >floor:
print(cv2.contourArea(contour))
rect = cv2.minAreaRect(contour)
rect_points = cv2.boxPoints(rect).astype(int)
rects.append(rect_points)
# 左上から右下順になるようにソート
rects = sorted(rects, key=lambda x: (x[1][1], x[0][0]))
for i in rects:
x1.append(min(i.T[0]))
x2.append(max(i.T[0]))
y1.append(min(i.T[1]))
y2.append(max(i.T[1]))
return x1,x2,y1,y2
これで、検出するための準備ができました。次に塗りつぶせるか確認処理をします。
# 4つの座標を受け取って白く塗るための関数
※Qは塗ったり、確認するための色を決める値です。
※drawは-1で塗りつぶし、整数で囲む太さを決めます。
def In_white(file,x1,x2,y1,y2, Q, draw):
img = cv2.imread(file)
for x,X,y,Y in zip(x1,x2,y1,y2):
if x < img.shape[1]/3:
img = cv2.rectangle(img,(0,0),(X+5,Y+5), Q, draw)
else:
img = cv2.rectangle(img,(x-5,0),(img.shape[1], img.shape[0]), Q, draw)
return img
確認する場合はQを黒「Q=(255,255,255)」としてdrawを四角で囲む「draw=1」とすれば囲んでくれます。
実際に実行
- outputフォルダをまんまコピー、deepフォルダを作成します。
import os
import shutil
if os.path.exists("./deep"):
folda_deep_list = os.listdir("./deep")
for folda in folda_deep_list:
shutil.rmtree("./deep/" + folda)
shutil.rmtree("./deep")
shutil.copytree("./setting/output","./deep")
import cv2
import glob
from matplotlib import pyplot as plt
%matplotlib inline
Q = (255,255,255)
draw = 1
# 必ず確認
folda_deep_list = os.listdir("./deep")[1:]
for folda in folda_deep_list:
# 白紙画像ファイルを取得
file="./deep/" + folda + "/white.jpg"
print(folda)
# 番号の座標検出
x1,x2,y1,y2,gray = Kensyutu(file,floor=100)
img_w=In_white(file,x1,x2,y1,y2, Q, draw)
print(img_w.shape)
plt.imshow(img_w,"gray")
plt.show()
こんな感じで出力してくれました。
うまく行っていれば、Qの値を白(0,0,0)に、drawを-1にして実行すればOKです。
問題点があります
うまく検出されない問題
ノイズがひどいと、よくわかんないとこが検出されたり、大きく検出されすぎたりすることがあります。 その場合はペイントで編集するのがベストです。画像を白でぬりたくって行えばうまく検出してくれます。若干手間なのが難点ですが、、、
あくまで基準は白紙の解答用紙
座標で管理している以上、ずれが生じるの一番の難点です。あまりにもずれていると、半分しか隠れていないなんてこともありました。座標+5くらいしてあげてもいいかもしれません。
解答を隠してしまう可能性
問題番号の下やその付近に解答があるばあい、当然それも隠れてしまいます。。。これについては諦めました。。。
いやいや、そもそも番号を区切ればいいだけの話では?
やっていて思ったのは、解答用紙に予め、解答欄の番号と解答を書く場所の間に縦線をいれておけばいいのかもしれません。しかし、それだと自動検出に支障が出そうです。一度、試してみようとは思っています。
そして、問題番号を含まないようにすればいいだけの話。わざわざPythonで処理しなくても、作りてに一工夫あれば解決しそうです。
今回は以上です。ありがとうございました。
目指せ自動採点!【まとめ編】
ブログの紹介
このブログは現役教員が独学でプログラミング(Python)を学習して採点アプリを作ろうと思い、試行錯誤しながら作成にあたっております。そして、学んだことをアウトプットすることで、意味を理解しようという目的で書き残しています。 そして完成にあたり、欠かせないのが「採点斬り」)。こちらをフル活用しつつ、作成にあたっております^^
自動採点までの流れ
自動採点をするにはいくつかの弊害がありました。
- 解答欄の問題番号が邪魔
- 解答欄の線がのこる
- 切り取った解答欄のノイズが邪魔
この弊害をうまく処理して自動採点にチャレンジします。
自動採点でできたこと
上の3つの処理を実行した後、今回自動採点でできたのは以下の通りです。
※精度は私の肌感です。根拠はやってみた感想で数値にしています。
- 白紙と白紙じゃないの区別(精度95%)
- ひらがな、○×の判定(ひらがな:精度70%)(○×:精度95%)
- 数式の判定(外部の神アプリ(MathPix)を利用:精度90%)
全体の感想
白紙の区別に関しては中々うまくできたなという感じがしています。
ただ、ひらがな、○×判定はディープラーニングを利用しているので、まずはデータ集めをして、随時学習していかせる必要があるなぁと思いました。○×は単純なので良いのですが、ひらがなは「あ」と「お」や「き」と「さ」の区別はどおしても難しい・・・
なので、この部分に関してはマークシートの形式にして、選択させるのがベストでは?と思いました。
数式についてはいろんなサイトにあるgithubを参考にして実行してみましたが、エラーがでたり、やっとうまくいったと思っても精度が悪かったり、正確さを要求される採点には不向きでした。
そこで、外部のアプリMathPixを利用させてもらう事にしました。元画像さえよければ精度は抜群に良いです。
これから随時更新していき・・・ます。(^^;
採点アプリを作ろう!【解答用紙に○×△をつける(OpenCV)】
はじめに
採点斬りでは、採点終了後、配点を表示するかわりに〇×△マークがついていませんでした。そこでOpenCVを使って、マークをつけるよう、コードを組んでみました。
採点がすべて完了し、解答用紙の出力まで終わった後に実行します。
完成形
※採点は超絶適当につけています。
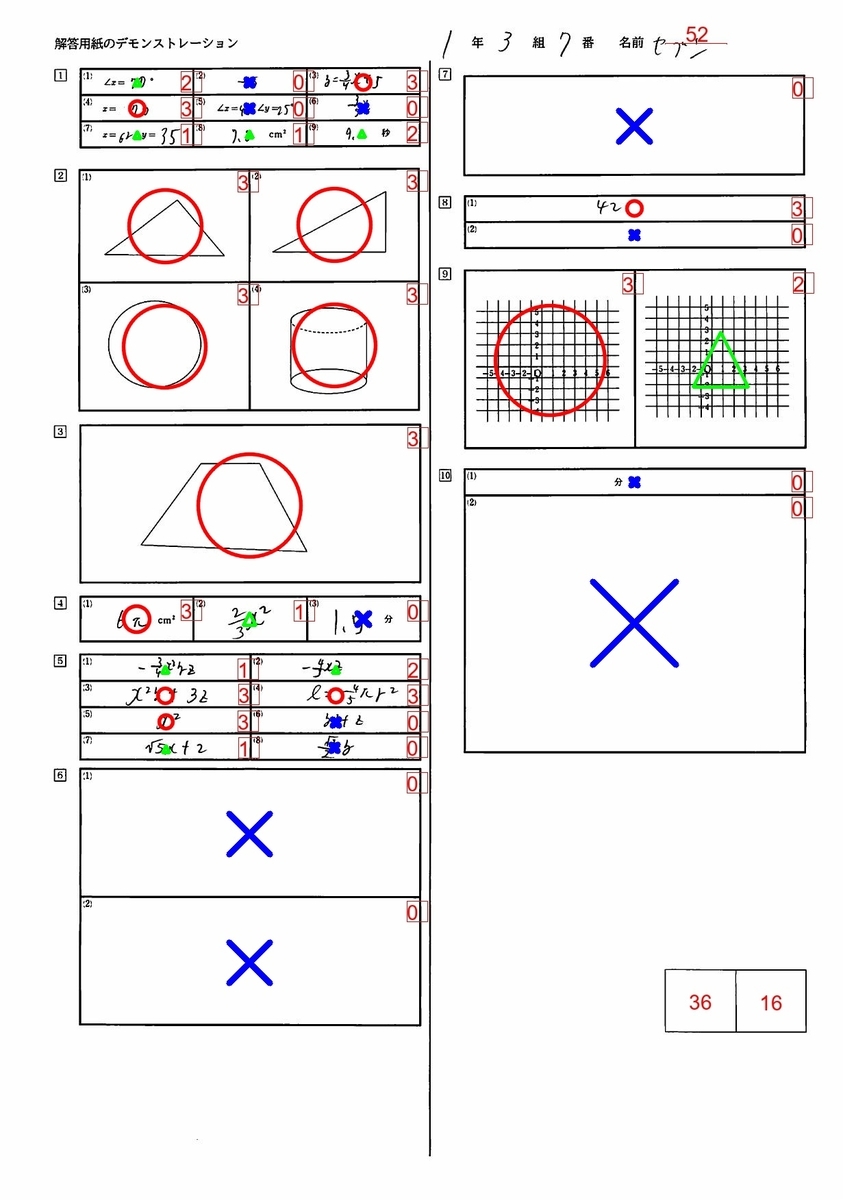
コードのおおまかな方針
trimDataから座標を取得し、そこからマークの大きさをきめています。また、○×△はKaitoYoushiフォルダの配点フォルダ情報を取得し、そこから分類して○×△を決めています。
不完全なところ
仮に×なし、〇のみやその逆が起こった場合に対応ができていません。まぁ、あらかじめ、0点の用紙と満点の用紙を用意しておけば、そのようなことは起きないのでいいかなと思っています。 ではコード↓
def Saiten_mark()
if os.path.exists("./setting/kaitoYousi/saiten"):
shutil.rmtree("./setting/kaitoYousi/saiten")
df_zahyo = pd.read_csv("./setting/trimData.csv", index_col=0)
Jpg_list = os.listdir("./setting/kaitoYousi")
daimon_list = df_zahyo.index[1:-2]
df_zahyo = df_zahyo.T
for jpg in Jpg_list:
# 画像を読み込む
img = cv2.imread("./setting/kaitoYousi/" + jpg)
# 問題番号リストで回す
for daimon in daimon_list:
# 問題番号の座標を取得
x_s,y_s,x_g,y_g=df_zahyo[daimon]
x= round(x_s+(x_g-x_s)/2)
y=round(y_s+(y_g-y_s)/2)
# 大きさによって〇のサイズを変える
if x_g-x_s < y_g-y_s:
size = (x_g-x_s)/3
elif y_g-y_s < x_g-x_s:
size = (y_g-y_s)/3
# 大問フォルダの中の配点フォルダ名を取得
haiten_list=os.listdir("./setting/output/"+daimon)
# 0点フォルダは最初
haiten_0 = haiten_list[0]
# 0点フォルダのpass
img_path_0 = daimon +"/"+ haiten_0 + "/" + jpg
# バツを付ける
if os.path.exists("./setting/output/" + img_path_0):
img = cv2.drawMarker(img, (x, y), (255, 0, 0), thickness=8, markerType=cv2.MARKER_TILTED_CROSS, markerSize=int(size))
else:
pass
# 正解フォルダは最後
haiten_cor = haiten_list[-1]
# 正解フォルダのpass
img_path_cor = daimon +"/"+ haiten_cor + "/" + jpg
# 丸を付ける
if os.path.exists("./setting/output/" + img_path_cor):
img = cv2.circle(img, (x, y), int(size), (0, 0, 255), thickness=3, lineType=cv2.LINE_AA)
else:
pass
# もし配点フォルダが2つなら、○×のみなのでpassする。
if len(haiten_list) == 2:
pass
else:
haiten_bubun = haitenlist[1:-1]
for bubun in haiten_bubun:
img_path_bubun = daimon +"/"+ bubun + "/" + jpg
# 三角を付ける
if os.path.exists("./setting/output/" + img_path_bubun):
img = cv2.drawMarker(img, (x, y), (0, 255, 0), thickness=3, markerType=cv2.MARKER_TRIANGLE_UP, markerSize=int(size))
else:
pass
# セーブする
if not os.path.exists("./setting/kaitoYousi/saiten"):
os.makedirs("./setting/kaitoYousi/saiten")
cv2.imwrite("./setting/kaitoYousi/saiten"+"/"+ jpg, img)
採点アプリをつくろう!【まとめ編】
前提とこのブログの大まかな内容
中間、期末考査の採点は本当に大変です。一人で100枚以上の答案を懇切、丁寧に採点しなければなりません。その中でも何が大変で何が楽しいのかを見極め、自分なりに解決策を模索しました。
採点で大変なこと
- とにかく単純な作業
マル、マルマル、バツ、マル、、、
永遠と続くこの作業も30枚ほどやると飽きてきます。ミスも出始めます。。。大変です。 - 「この解答△だけど、何点にすればいいんだ?」
いわゆる部分点問題です。バツではないけど、マルでもない、、、
そのような解答によく出くわします。そして、何点つけたか忘れます。(模範解答とかにメモとかして対処しますが、、、)毎回、最後に確認しますが大変です。 - 時間がかかる
テスト終了したら大抵、土日を潰して採点しています。でないと終わりません。これがたまらなく嫌ではありますが、やらなければ終わりません。部活の大会とかあると更にカオスと化します。
採点で楽しいこと
正直、めんどくさいが勝っていて、見出すのが難しいです。でも、間違いの傾向を分析したり、何ができていて、何が難しいと感じているのか。教科ならではの分析ができると、楽しいだろうなと思っています。分析なら、PythonまたはRといったところでしょうか。ここも狙っていきたいですね。
マークシートでいいのでは?
マークシートにしてしまえばすべて解決ですが、年数回の定期考査で記述なしというのはさすがに現実的ではありません。また、市販のだと指定の用紙でないとダメなど、テスト制作の自由性がありませんし、ドケチな私にとってはランニングコストに気が引けます、、、 そこで、「Python」を学び、今現在、この問題解決に向けて勉強しています。
でたものはgithubへ
私が作成したものはgithubにあります。(こちらから) あがっている物の概要は以下の通りです。
kiritori.py
私が書いたコードになります。切り取り、PDFの変換等の関数を保存しております。
kousa.py
こちらは採点斬りの作成者であるphis-kenさんが公開しているものを、少しだけ弄りました。本家の素晴らしいアプリはこちらから。
私とは違い、自分自身だけでなく、幅広い方に対応できるように作られてあります。プログラミングの知識がない方でも利用することができます。ぜひ、参考にしてみてください。
my_gragh.py
PythonやRは分析の醍醐味ですよね。せっかく採点をPC上でできるようにしたのだから、分析もしっかり行っていきます。主にグラフ作成ツールとなっています。
white.pdf seito.pdf
white.pdfはmain1.pdfで使います。数学の解答用紙を扱うため、図形がかき込んであると自動検出に支障がでるため、あえて、白紙を用意してあります。 実際に使う解答用紙はseito.pdfの最後にベースとなる解答用紙が入っています。 (※seito.pdfにかいてある落書きは私が適当に描いたものです)
seito_meibo.csv
名簿データはあえて別で作成しています。テスト当日欠席や出席番号の関係で別で作成しておく必要があるため作成しています。
main1.py
こちらは、解答用紙を自動検出し、切り取るための準備をしています。(テスト始まる前までの処理となります。)
こちらの画像が参考になります。
main1.pyの解説はこちらから
al31ufa4.hatenablog.com
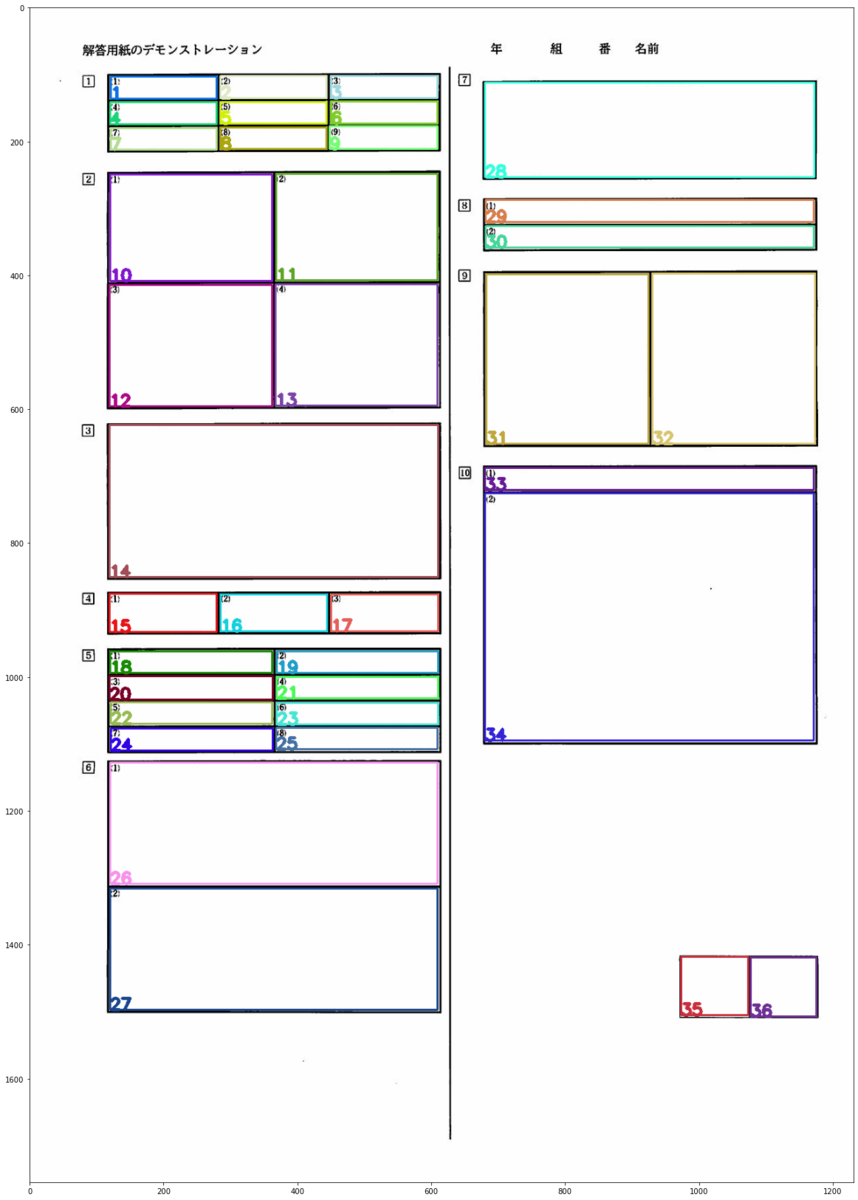
main2.py
こちらはmain1の処理を元に、生徒の画像データを切り取り、白紙の解答は0点フォルダに格納しています。(テスト終了後の処理になります。)
こちらの画像が参考になります。
~切り取り直後~

~移動後~


~ここで採点~
kousa.pyを起動して、採点に入ります。

main3.py
採点終了後、グラフをかくためにデータをテーブルにまとめています。いろいろと使えると思ったので、あえて分けています。

main4.py
グラフを簡単にかくため、関数にしてまとめました。こちらも随時更新と訂正していきたいと思っています。

今後の展望
まずは、解答の採点に〇△×をつけたいなと思っています。(今現在は解答欄の右上に配点が表示されるようになっています。) ⇒つけることができました!!!
他にもOCRをつかって 自動採点ができるようになれば、更に詳しい分析だったり、小テストの回数を多く増やすことにも抵抗が少なくなりそうです。PythonやRをもっと極めていきたいと思っています。
採点アプリを作ろう!【main1.pyの一部解説】
はじめに
@phys-kenさんが作ってくださった採点斬りというものをもとに自分が付け加えできる事がないかを考えました。(詳細はサイトにて確認して頂ければと思います。 )
目次
- はじめに
- 目次
- 切り取りの自動化概要
- 用意しておくことや準備と注意
- 【namelist作成】大問小問の数を確認,切り取りと保存
- 【いよいよ自動切りとり】各小問の座標を取得する
- 【順番整理】各小問の並び替え
- 【本当にできたのか?】目で見て確認する
- trimDataと結合
切り取りの自動化概要
採点斬りの中で大変だと思ったのが、解答欄が多くなればなるほど、切るのがめんどくさくなったり、切りぬきずらいことがあり、それを自動化しちゃおうぜ!って感じです。 大雑把に方針を言いますと、解答用紙を左上原点$(0, 0)$である座標平面に置き、すべての解答欄の頂点の座標を割り出していきます。そしてその座標を採点斬りで作成される「trimData.csv」とがっしゃんこします^^
用意しておくことや準備と注意
【用意や準備】
【注意】私の解答用紙を元にしているため、何点か注意があります。
- 面積の最小の割合は適宜微調整する。(floorの値)⇒大問が反応しないなら下げる。反応しすぎるなら上げる。
- 解答用紙の縦と横のラインはなるべく揃えておく。⇒座標で処理するため、ずれがひどいと順番がめちゃくちゃになる恐れあり。
- 今回は数研出版のソフトstudiaidで作った解答用紙になります。
- 小問番号を囲ってしまうとその箇所も小問と反応してしまうことがあるので注意が必要。(今回は外しました。)
# 使うモジュール import os import cv2 from matplotlib import pyplot as plt %matplotlib inline import numpy as np import pandas as pd import glob
パスを入力。画像と名簿が読み取れているか確認
PATH="base.jpgが置いてあるファイルまで移動"
os.chdir(PATH)
# 名簿を読み込む
# 名簿リストを作成する。※日本語は文字化け等もあるので避けておく。
df = pd.read_csv("base.csv")
df =df.astype(str)
df2=df["年"]+"-"+df["組"]+"-"+df["番号"]
namelist=df2.tolist()
# 画像ファイルを取得
file="base.jpg"
img = cv2.imread(file)
fig = plt.figure(figsize=(20,32))
plt.imshow(img)
今回のbase.jpgはこちら
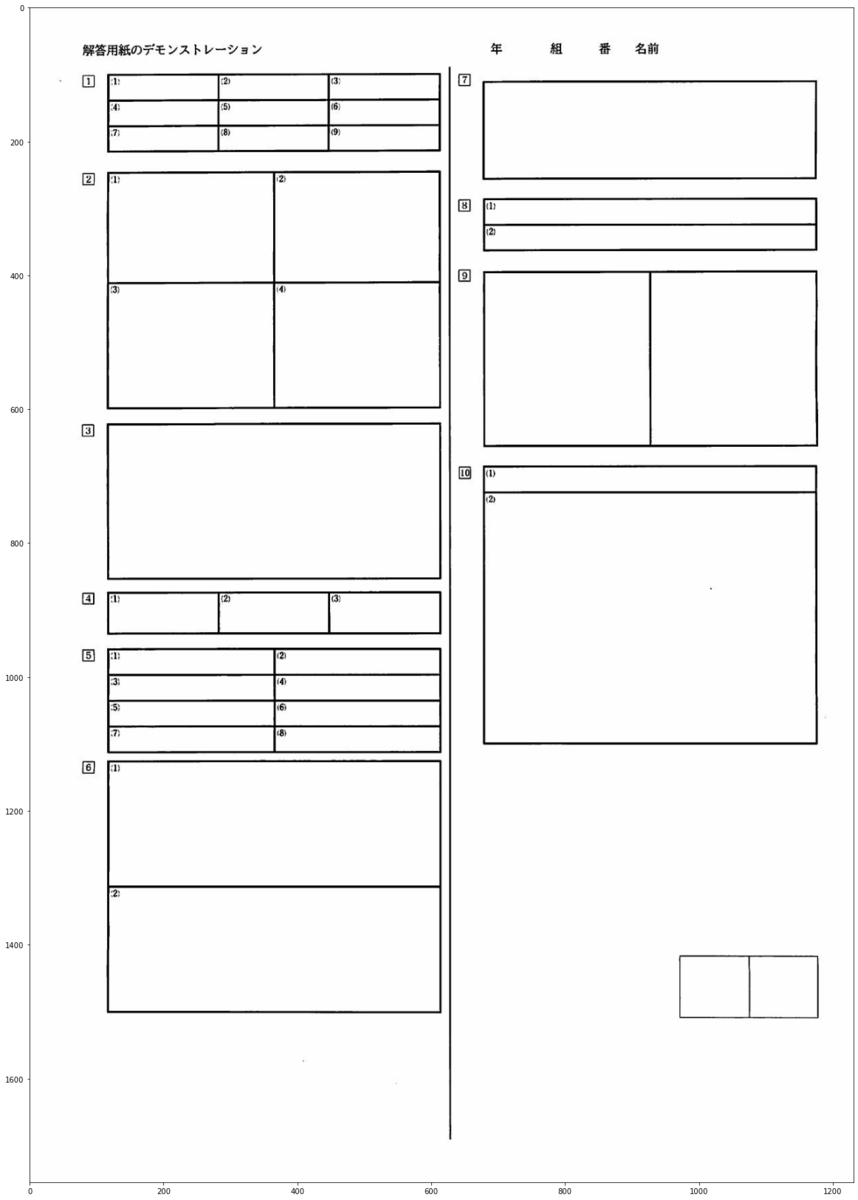
【namelist作成】大問小問の数を確認,切り取りと保存
※ここのフェーズはあくまで確認用。自分が一つ一つ確認して行った実行のもの。ほとんどが無意味だが、namelistは後半で使うので実行が必要。 【行う事】 大問画像の切り取り、大問の中の小問画像を切り取り、ついでに大問nの小問mというnamelistの作成
# まとめ座標
zahyoulist=[]
# 大問〇の△問目のリスト
namelist=[]
# 画像の読み込み、加工
img = cv2.imread(file)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_gray = cv2.fastNlMeansDenoising(img_gray, h=5)
img_adth = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 43, 3)
img_adth_er = cv2.bitwise_not(img_adth)
# 図形の検出(解答欄の番号や文字も検出します。)
contours, _ = cv2.findContours(img_adth_er, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 解答欄の面積を割り出す。また、大問毎の座標4つをzahyoulistに格納。それぞれの座標も格納する。
# 最小(大問のみを抽出したいのでここの面積の最小の値は大きめに設定)
floor =10000
# 最大
ceil = 10000000
for i, rect in enumerate(contours):
# 指定範囲内(ceil未満、floorより上)の面積(ピクセル)のみをカウントさせる。
if cv2.contourArea(rect) > floor and ceil > cv2.contourArea(rect):
# x座標, y座標, 横の長さw,縦の長さhの情報をcv2.boundingRect(rect)で取得する。
x, y, w, h = cv2.boundingRect(rect)
x_end=x+w
y_end=y+h
zahyoulist.append([x, x_end, y, y_end])
# x座標に着目し、画像の半分以下のものと、半分より大きいものに分けて別のリストに格納する
# 分けたものをZリストにくっつける。
y=[]
Z=[]
for i in range(len(zahyoulist)):
if zahyoulist[i][0] < img.shape[1]//2:
y.append(zahyoulist[i])
y.sort(key = lambda y: y[2], reverse=False)
for i in range(len(zahyoulist)):
if zahyoulist[i][0] > img.shape[1]//2:
Z.append(zahyoulist[i])
Z.sort(key = lambda Z: Z[2], reverse=False)
for i in range(len(Z)):
y.append(Z[i])
# 大問を切り分けて保存
for i in range(len(y)):
x, x_end, t, t_end = y[i]
#このimg_tissueが切った大問画像
img_tissue = img[t:t_end, x:x_end]
# 画像保存処理。確認したい場合はコメントアウトを外す。
# out_dir_suf = f"\\CUT_NO{i+1}"
# out_dir = str(PATH + out_dir_suf)
# if not os.path.exists(out_dir):
# os.makedirs(out_dir)
# cv2.imwrite(out_dir + f"\\base_NO{i+1}.jpg",img_tissue)
# ここからは、切り取った大問を小問にして処理していく。
# 画像処理
gray = cv2.cvtColor(img_tissue, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
binary = cv2.dilate(binary, kernel)
# 図形の検出
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
rects = []
small_floor=4000
# 面積で場合分け
for cnt, hrchy in zip(contours, hierarchy[0]):
if cv2.contourArea(cnt) < small_floor:
continue # 面積が小さいものは除く
if hrchy[3] == -1:
continue # ルートノードは除く
# 輪郭を囲む長方形を計算する。
rect = cv2.minAreaRect(cnt)
rect_points = cv2.boxPoints(rect).astype(int)
rects.append(rect_points)
# 左上から右下順になるようにソート
rects = sorted(rects, key=lambda x: (x[1][1], x[0][0]))
print(f"大問{i+1}の小問の数{len(rects)}")
# 切り取り処理
for num in range(len(rects)):
namelist.append(f"NO{i+1}-{num+1}")
x1=min(rects[num].T[0])
x2=max(rects[num].T[0])
y1=min(rects[num].T[1])
y2=max(rects[num].T[1])
# このimg_tissue2が切った小問画像
img_tissue_2 = img_tissue[y1:y2, x1:x2]
# 保存処理
# out_dir_suf2 = f"\\small_question"
# out_dir2 = str(out_dir + out_dir_suf2)
# if not os.path.exists(out_dir2):
# os.makedirs(out_dir2)
# cv2.imwrite(out_dir2 + f"\\base_no{num+1}.jpg",img_tissue_2)
print(f"大問数は{len(X1_list)}、小問の数は{len(namelist)}です。")
出力結果がこちら
大問1の小問の数9 大問2の小問の数4 大問3の小問の数1 大問4の小問の数3 大問5の小問の数8 大問6の小問の数2 大問7の小問の数1 大問8の小問の数2 大問9の小問の数2 大問10の小問の数2 大問11の小問の数2 大問数は11、小問の数は36です。
大問数が11なのは、観点別の点数を入力する欄がカウントされているからです。 ここの検出は大問で大枠を把握したあと、小問の切り取りを行っているので、大問の数さえあっていれば、小問のカウントはほぼ確実に行えているかと思います。今回は小問数36個です
【いよいよ自動切りとり】各小問の座標を取得する
PATH_base="base.jpgがあるフォルダのパス"
os.chdir(PATH_base)
# 検出する面積の値を設定
square=4000
# 小問画像の座標を入れるリストを作成
x1_list=[]
x2_list=[]
y1_list=[]
y2_list=[]
# 画像の編集
img = cv2.imread(file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
binary = cv2.dilate(binary, kernel)
# 図形の検出
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
rect_small = []
# 面積で場合分け
for cnt, hrchy in zip(contours, hierarchy[0]):
if cv2.contourArea(cnt) < square:
continue # 面積が小さいものは除く
if hrchy[3] == -1:
continue # ルートノードは除く
rectsmall = cv2.minAreaRect(cnt)
rect_smallpoints = cv2.boxPoints(rectsmall).astype(int)
rect_small.append(rect_smallpoints)
print(f"小問題の数の合計{len(rect_small)}個です。合っていますか?")
print("多い場合は面積の値を上げ、少ない場合は下げてください。")
for num in range(len(rect_small)):
x1=min(rect_small[num].T[0])
x2=max(rect_small[num].T[0])
y1=min(rect_small[num].T[1])
y2=max(rect_small[num].T[1])
x1_list.append(x1)
x2_list.append(x2)
y1_list.append(y1)
y2_list.append(y2)
出力がこちら
小問題の数の合計36個です。合っていますか? 多い場合は面積の値を上げ、少ない場合は下げてください。
さっきの実行でも今回の実行でも小問の数が36個無事、切り取りは行えました^^
【順番整理】各小問の並び替え
今はただ切り取っただけなので、順番がバラバラです。なので大問1なら大問1の小問でかため、さらに小問毎に並び替えがしたいです!ここでも小問の各頂点の座標を元に並び替えをしていきます。 しかし、解答用紙作る際に、ずらしたりするとどうしてもラインに誤差がでてしまう。 今回も大問1の(1)~(3)でy座標が1ずれており、(2)(3)(1)という並び順になっていたので、それを解消し、(座標のずれ1~5程度)の誤差なら対応できるよう工夫してみました)
( ^ω^)・・・採点はどこから行ってもいいため、ぶっちゃけ準番通りにする必要はないのだが、気持ちとして順番にするならどうかなと思い、実装してみました。
lists = [x1_list, y1_list, x2_list, y2_list]
df = pd.DataFrame(lists, index=["start_x","start_y", "end_x","end_y"]).T
# 二段に分ける
df.loc[df['end_x'] < img.shape[1]/2, 'label'] = 'left'
df.loc[df['end_x'] > img.shape[1]/2, 'label'] = 'right'
# 左半分
df1=df[df["label"]=="left"]
# yの値で高さを小さい順にした後、xの値で小さい順に
df1_sort=df1.sort_values(["end_y","start_x"])
# ただし、yの値でsortしても誤差が1~5あるので、その部分は許容するようにラベル付けをして調整する。
df1_sort["立幅フラグ"]=0
label = 1
for i in range(df1_sort.shape[0]):
# 上としたのy座標5までのずれは誤差と判定し、同じとみなすラベルをつける
gosa = df1_sort[["end_y"]].iloc[i]-df1_sort[["end_y"]].iloc[i-1]
if gosa[0] < 5:
df1_sort["立幅フラグ"].iloc[i] = label
else:
# 5より大きい場合は次の行に移ったと判定し別ラベルにする
label+=1
df1_sort["立幅フラグ"].iloc[i] = label
df1_sort=df1_sort.sort_values(["立幅フラグ","start_x"])
# 右半分も同様に行う。
df2=df[df["label"]=="right"]
df2_sort=df2.sort_values(["end_y","start_x"])
# sortしても、誤差が1~5あるので調整
df2_sort["立幅フラグ"]=0
label = 1
for i in range(df2_sort.shape[0]):
gosa = df2_sort[["end_y"]].iloc[i]-df2_sort[["end_y"]].iloc[i-1]
if gosa[0] < 5:
df2_sort["立幅フラグ"].iloc[i] = label
else:
label+=1
df2_sort["立幅フラグ"].iloc[i] = label
df2_sort=df2_sort.sort_values(["立幅フラグ","start_x"])
df3=pd.concat((df1_sort,df2_sort),axis=0).drop(columns="label").reset_index(drop=True)
NO = df3.index.tolist()
NEW=[]
for i, j in zip(namelist,NO) :
# 採点斬りは後ろ4桁の数字でないと採点出力の際にエラー判定となるため、ラベルを付けておく。
NEW.append(f"{i}_{str(j+1).zfill(4)}")
df3.index=NEW
df3 = df3.drop(["立幅フラグ"],axis=1)
これで、df3にすべての小問が順番通りにDataFrameとして格納されました。
【本当にできたのか?】目で見て確認する
しっかり順番通りになっているかを確認してみます。
# 描画する。
img = cv2.imread(file_name)
new_rect=[]
for i in range(len(df3.index)):
new_rect.append(np.array([[df3.iloc[i][0],df3.iloc[i][3]],
[df3.iloc[i][0],df3.iloc[i][1]],
[df3.iloc[i][2],df3.iloc[i][1]],
[df3.iloc[i][2],df3.iloc[i][3]]]))
for i, rect in enumerate(new_rect):
color = np.random.randint(0, 255, 3).tolist()
cv2.drawContours(img, new_rect, i, color, 2)
cv2.putText(img, str(i+1), tuple(rect[0]), cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 3)
fig = plt.figure(figsize = (20,32))
plt.imshow(img)
やったぜ!
trimDataと結合
※あらかじめ、名前データは切り取った状態にしておく。
PATH_trim="trimData.csvがあるパスを入力"
os.chdir(PATH_trim)
file_name="trimData.csv"
df_trim= pd.read_csv(file_name, index_col=0)
df_newtrim = pd.concat((df_trim[:1], df3), axis=0)
df_newtrim.to_csv("trimData.csv", encoding="utf-8", index=True)
一度プログラムを組んでしまえばあとは自動化できる。プログラミングの醍醐味ですね! 以上です!