採点アプリを作ろう!【main1.pyの一部解説】
はじめに
@phys-kenさんが作ってくださった採点斬りというものをもとに自分が付け加えできる事がないかを考えました。(詳細はサイトにて確認して頂ければと思います。 )
目次
- はじめに
- 目次
- 切り取りの自動化概要
- 用意しておくことや準備と注意
- 【namelist作成】大問小問の数を確認,切り取りと保存
- 【いよいよ自動切りとり】各小問の座標を取得する
- 【順番整理】各小問の並び替え
- 【本当にできたのか?】目で見て確認する
- trimDataと結合
切り取りの自動化概要
採点斬りの中で大変だと思ったのが、解答欄が多くなればなるほど、切るのがめんどくさくなったり、切りぬきずらいことがあり、それを自動化しちゃおうぜ!って感じです。 大雑把に方針を言いますと、解答用紙を左上原点$(0, 0)$である座標平面に置き、すべての解答欄の頂点の座標を割り出していきます。そしてその座標を採点斬りで作成される「trimData.csv」とがっしゃんこします^^
用意しておくことや準備と注意
【用意や準備】
【注意】私の解答用紙を元にしているため、何点か注意があります。
- 面積の最小の割合は適宜微調整する。(floorの値)⇒大問が反応しないなら下げる。反応しすぎるなら上げる。
- 解答用紙の縦と横のラインはなるべく揃えておく。⇒座標で処理するため、ずれがひどいと順番がめちゃくちゃになる恐れあり。
- 今回は数研出版のソフトstudiaidで作った解答用紙になります。
- 小問番号を囲ってしまうとその箇所も小問と反応してしまうことがあるので注意が必要。(今回は外しました。)
# 使うモジュール import os import cv2 from matplotlib import pyplot as plt %matplotlib inline import numpy as np import pandas as pd import glob
パスを入力。画像と名簿が読み取れているか確認
PATH="base.jpgが置いてあるファイルまで移動"
os.chdir(PATH)
# 名簿を読み込む
# 名簿リストを作成する。※日本語は文字化け等もあるので避けておく。
df = pd.read_csv("base.csv")
df =df.astype(str)
df2=df["年"]+"-"+df["組"]+"-"+df["番号"]
namelist=df2.tolist()
# 画像ファイルを取得
file="base.jpg"
img = cv2.imread(file)
fig = plt.figure(figsize=(20,32))
plt.imshow(img)
今回のbase.jpgはこちら
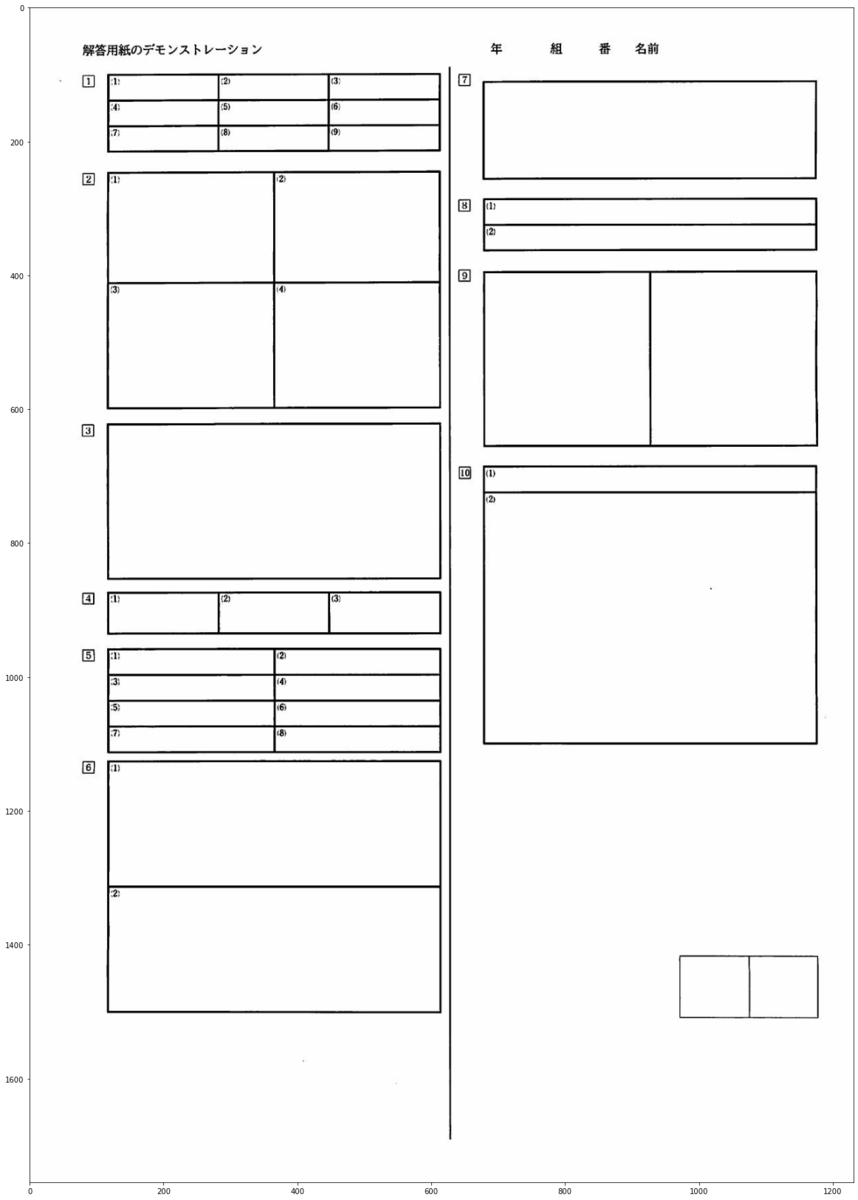
【namelist作成】大問小問の数を確認,切り取りと保存
※ここのフェーズはあくまで確認用。自分が一つ一つ確認して行った実行のもの。ほとんどが無意味だが、namelistは後半で使うので実行が必要。 【行う事】 大問画像の切り取り、大問の中の小問画像を切り取り、ついでに大問nの小問mというnamelistの作成
# まとめ座標
zahyoulist=[]
# 大問〇の△問目のリスト
namelist=[]
# 画像の読み込み、加工
img = cv2.imread(file)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_gray = cv2.fastNlMeansDenoising(img_gray, h=5)
img_adth = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 43, 3)
img_adth_er = cv2.bitwise_not(img_adth)
# 図形の検出(解答欄の番号や文字も検出します。)
contours, _ = cv2.findContours(img_adth_er, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 解答欄の面積を割り出す。また、大問毎の座標4つをzahyoulistに格納。それぞれの座標も格納する。
# 最小(大問のみを抽出したいのでここの面積の最小の値は大きめに設定)
floor =10000
# 最大
ceil = 10000000
for i, rect in enumerate(contours):
# 指定範囲内(ceil未満、floorより上)の面積(ピクセル)のみをカウントさせる。
if cv2.contourArea(rect) > floor and ceil > cv2.contourArea(rect):
# x座標, y座標, 横の長さw,縦の長さhの情報をcv2.boundingRect(rect)で取得する。
x, y, w, h = cv2.boundingRect(rect)
x_end=x+w
y_end=y+h
zahyoulist.append([x, x_end, y, y_end])
# x座標に着目し、画像の半分以下のものと、半分より大きいものに分けて別のリストに格納する
# 分けたものをZリストにくっつける。
y=[]
Z=[]
for i in range(len(zahyoulist)):
if zahyoulist[i][0] < img.shape[1]//2:
y.append(zahyoulist[i])
y.sort(key = lambda y: y[2], reverse=False)
for i in range(len(zahyoulist)):
if zahyoulist[i][0] > img.shape[1]//2:
Z.append(zahyoulist[i])
Z.sort(key = lambda Z: Z[2], reverse=False)
for i in range(len(Z)):
y.append(Z[i])
# 大問を切り分けて保存
for i in range(len(y)):
x, x_end, t, t_end = y[i]
#このimg_tissueが切った大問画像
img_tissue = img[t:t_end, x:x_end]
# 画像保存処理。確認したい場合はコメントアウトを外す。
# out_dir_suf = f"\\CUT_NO{i+1}"
# out_dir = str(PATH + out_dir_suf)
# if not os.path.exists(out_dir):
# os.makedirs(out_dir)
# cv2.imwrite(out_dir + f"\\base_NO{i+1}.jpg",img_tissue)
# ここからは、切り取った大問を小問にして処理していく。
# 画像処理
gray = cv2.cvtColor(img_tissue, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
binary = cv2.dilate(binary, kernel)
# 図形の検出
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
rects = []
small_floor=4000
# 面積で場合分け
for cnt, hrchy in zip(contours, hierarchy[0]):
if cv2.contourArea(cnt) < small_floor:
continue # 面積が小さいものは除く
if hrchy[3] == -1:
continue # ルートノードは除く
# 輪郭を囲む長方形を計算する。
rect = cv2.minAreaRect(cnt)
rect_points = cv2.boxPoints(rect).astype(int)
rects.append(rect_points)
# 左上から右下順になるようにソート
rects = sorted(rects, key=lambda x: (x[1][1], x[0][0]))
print(f"大問{i+1}の小問の数{len(rects)}")
# 切り取り処理
for num in range(len(rects)):
namelist.append(f"NO{i+1}-{num+1}")
x1=min(rects[num].T[0])
x2=max(rects[num].T[0])
y1=min(rects[num].T[1])
y2=max(rects[num].T[1])
# このimg_tissue2が切った小問画像
img_tissue_2 = img_tissue[y1:y2, x1:x2]
# 保存処理
# out_dir_suf2 = f"\\small_question"
# out_dir2 = str(out_dir + out_dir_suf2)
# if not os.path.exists(out_dir2):
# os.makedirs(out_dir2)
# cv2.imwrite(out_dir2 + f"\\base_no{num+1}.jpg",img_tissue_2)
print(f"大問数は{len(X1_list)}、小問の数は{len(namelist)}です。")
出力結果がこちら
大問1の小問の数9 大問2の小問の数4 大問3の小問の数1 大問4の小問の数3 大問5の小問の数8 大問6の小問の数2 大問7の小問の数1 大問8の小問の数2 大問9の小問の数2 大問10の小問の数2 大問11の小問の数2 大問数は11、小問の数は36です。
大問数が11なのは、観点別の点数を入力する欄がカウントされているからです。 ここの検出は大問で大枠を把握したあと、小問の切り取りを行っているので、大問の数さえあっていれば、小問のカウントはほぼ確実に行えているかと思います。今回は小問数36個です
【いよいよ自動切りとり】各小問の座標を取得する
PATH_base="base.jpgがあるフォルダのパス"
os.chdir(PATH_base)
# 検出する面積の値を設定
square=4000
# 小問画像の座標を入れるリストを作成
x1_list=[]
x2_list=[]
y1_list=[]
y2_list=[]
# 画像の編集
img = cv2.imread(file)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
binary = cv2.dilate(binary, kernel)
# 図形の検出
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
rect_small = []
# 面積で場合分け
for cnt, hrchy in zip(contours, hierarchy[0]):
if cv2.contourArea(cnt) < square:
continue # 面積が小さいものは除く
if hrchy[3] == -1:
continue # ルートノードは除く
rectsmall = cv2.minAreaRect(cnt)
rect_smallpoints = cv2.boxPoints(rectsmall).astype(int)
rect_small.append(rect_smallpoints)
print(f"小問題の数の合計{len(rect_small)}個です。合っていますか?")
print("多い場合は面積の値を上げ、少ない場合は下げてください。")
for num in range(len(rect_small)):
x1=min(rect_small[num].T[0])
x2=max(rect_small[num].T[0])
y1=min(rect_small[num].T[1])
y2=max(rect_small[num].T[1])
x1_list.append(x1)
x2_list.append(x2)
y1_list.append(y1)
y2_list.append(y2)
出力がこちら
小問題の数の合計36個です。合っていますか? 多い場合は面積の値を上げ、少ない場合は下げてください。
さっきの実行でも今回の実行でも小問の数が36個無事、切り取りは行えました^^
【順番整理】各小問の並び替え
今はただ切り取っただけなので、順番がバラバラです。なので大問1なら大問1の小問でかため、さらに小問毎に並び替えがしたいです!ここでも小問の各頂点の座標を元に並び替えをしていきます。 しかし、解答用紙作る際に、ずらしたりするとどうしてもラインに誤差がでてしまう。 今回も大問1の(1)~(3)でy座標が1ずれており、(2)(3)(1)という並び順になっていたので、それを解消し、(座標のずれ1~5程度)の誤差なら対応できるよう工夫してみました)
( ^ω^)・・・採点はどこから行ってもいいため、ぶっちゃけ準番通りにする必要はないのだが、気持ちとして順番にするならどうかなと思い、実装してみました。
lists = [x1_list, y1_list, x2_list, y2_list]
df = pd.DataFrame(lists, index=["start_x","start_y", "end_x","end_y"]).T
# 二段に分ける
df.loc[df['end_x'] < img.shape[1]/2, 'label'] = 'left'
df.loc[df['end_x'] > img.shape[1]/2, 'label'] = 'right'
# 左半分
df1=df[df["label"]=="left"]
# yの値で高さを小さい順にした後、xの値で小さい順に
df1_sort=df1.sort_values(["end_y","start_x"])
# ただし、yの値でsortしても誤差が1~5あるので、その部分は許容するようにラベル付けをして調整する。
df1_sort["立幅フラグ"]=0
label = 1
for i in range(df1_sort.shape[0]):
# 上としたのy座標5までのずれは誤差と判定し、同じとみなすラベルをつける
gosa = df1_sort[["end_y"]].iloc[i]-df1_sort[["end_y"]].iloc[i-1]
if gosa[0] < 5:
df1_sort["立幅フラグ"].iloc[i] = label
else:
# 5より大きい場合は次の行に移ったと判定し別ラベルにする
label+=1
df1_sort["立幅フラグ"].iloc[i] = label
df1_sort=df1_sort.sort_values(["立幅フラグ","start_x"])
# 右半分も同様に行う。
df2=df[df["label"]=="right"]
df2_sort=df2.sort_values(["end_y","start_x"])
# sortしても、誤差が1~5あるので調整
df2_sort["立幅フラグ"]=0
label = 1
for i in range(df2_sort.shape[0]):
gosa = df2_sort[["end_y"]].iloc[i]-df2_sort[["end_y"]].iloc[i-1]
if gosa[0] < 5:
df2_sort["立幅フラグ"].iloc[i] = label
else:
label+=1
df2_sort["立幅フラグ"].iloc[i] = label
df2_sort=df2_sort.sort_values(["立幅フラグ","start_x"])
df3=pd.concat((df1_sort,df2_sort),axis=0).drop(columns="label").reset_index(drop=True)
NO = df3.index.tolist()
NEW=[]
for i, j in zip(namelist,NO) :
# 採点斬りは後ろ4桁の数字でないと採点出力の際にエラー判定となるため、ラベルを付けておく。
NEW.append(f"{i}_{str(j+1).zfill(4)}")
df3.index=NEW
df3 = df3.drop(["立幅フラグ"],axis=1)
これで、df3にすべての小問が順番通りにDataFrameとして格納されました。
【本当にできたのか?】目で見て確認する
しっかり順番通りになっているかを確認してみます。
# 描画する。
img = cv2.imread(file_name)
new_rect=[]
for i in range(len(df3.index)):
new_rect.append(np.array([[df3.iloc[i][0],df3.iloc[i][3]],
[df3.iloc[i][0],df3.iloc[i][1]],
[df3.iloc[i][2],df3.iloc[i][1]],
[df3.iloc[i][2],df3.iloc[i][3]]]))
for i, rect in enumerate(new_rect):
color = np.random.randint(0, 255, 3).tolist()
cv2.drawContours(img, new_rect, i, color, 2)
cv2.putText(img, str(i+1), tuple(rect[0]), cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 3)
fig = plt.figure(figsize = (20,32))
plt.imshow(img)
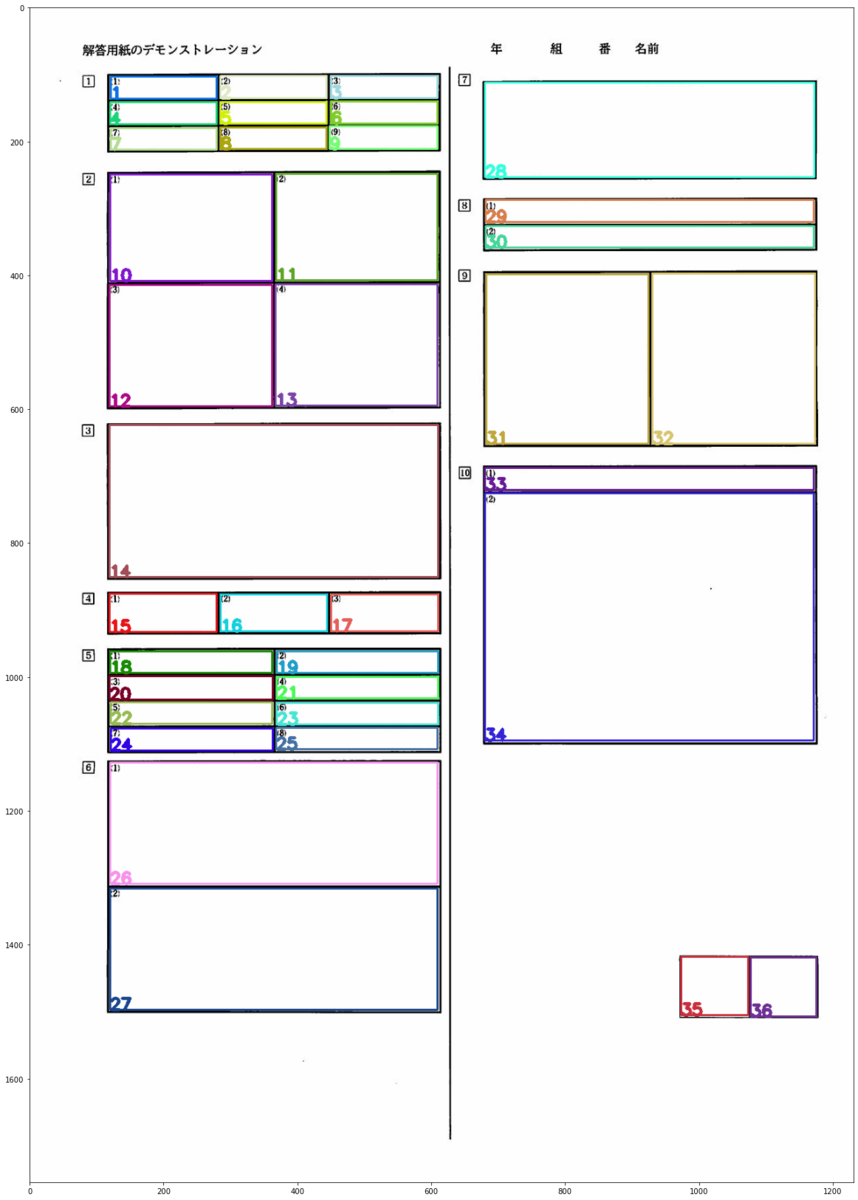
やったぜ!
trimDataと結合
※あらかじめ、名前データは切り取った状態にしておく。
PATH_trim="trimData.csvがあるパスを入力"
os.chdir(PATH_trim)
file_name="trimData.csv"
df_trim= pd.read_csv(file_name, index_col=0)
df_newtrim = pd.concat((df_trim[:1], df3), axis=0)
df_newtrim.to_csv("trimData.csv", encoding="utf-8", index=True)
一度プログラムを組んでしまえばあとは自動化できる。プログラミングの醍醐味ですね! 以上です!